我博客服务器使用的OpenSSL是1.0.1e版本,之所以需要升级到OpenSSL 1.0.1t版本是因为1.0.1t版本以下存在一个严重的Bug:Padding oracle in AES-NI CBC MAC check (CVE-2016-2107),我们可以到这里查看我们的网站是否有这个问题。官方对这个漏洞的描述是:[code lang="bash"]Padding oracle in AES-NI CBC MAC check (CVE-2016-2107)=============================================== w397090770 8年前 (2016-08-06) 2867℃ 0评论3喜欢
引言:把基于mapreduce的离线hiveSQL任务迁移到sparkSQL,不但能大幅缩短任务运行时间,还能节省不少计算资源。最近我们也把组内2000左右的hivesql任务迁移到了sparkSQL,这里做个简单的记录和分享,本文偏重于具体条件下的方案选择。迁移背景 SQL任务运行慢Hive SQL处理任务虽然较为稳定,但是其时效性已经达瓶颈,无法再进一 w397090770 3年前 (2021-10-19) 878℃ 0评论2喜欢
在《ASM 与 Presto 动态代码生成简介》这篇文章中,我们简单介绍了 Presto 动态代码生成的原理以及 Presto 在计算表达式的地方会使用到动态代码生成技术。为了加深理解,本文将以两个例子介绍 Presto 里面动态代码生成的使用。EmbedVersion我们往 Presto 提交 SQL 查询以及 TaskExecutor 启动 TaskRunner 执行 Task 的时候都会使用到 EmbedVersion 类 w397090770 3年前 (2021-10-12) 686℃ 0评论1喜欢
临时文件是一个暂时用来存储数据的文件。如果使用建立普通文件的方法来创建文件,则可能遇到文件是否存在,是否有文件读写权限的问题。Linux系统下提供的建立唯一的临时文件的方法如下:[code lang="CPP"]#include<stdio.h>char *tmpnam(char *s);FILE *tmpfile();[/code]函数tmpnam()产生一个唯一i的文件名。如果参量为NULL,则在一个内 w397090770 12年前 (2013-04-03) 5429℃ 0评论0喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ 如果你想查询某个表的某 w397090770 11年前 (2013-11-13) 17994℃ 4评论17喜欢
本文来自于2018年10月20日由中国 HBase 技术社区在武汉举办的中国 HBase Meetup 第六次线下交流会。分享者为过往记忆。本文 PPT 下载 请关注 iteblog_hadoop 微信公众号,并回复 HBase 获取。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公众号:iteblog_hadoop本次分享的内容主要分为以下五点:HBase基本知识;HBase读 w397090770 6年前 (2018-10-25) 6344℃ 0评论23喜欢
如果你使用 Spark RDD 或者 DataFrame 编写程序,我们可以通过 coalesce 或 repartition 来修改程序的并行度:[code lang="scala"]val data = sc.newAPIHadoopFile(xxx).coalesce(2).map(xxxx)或val data = sc.newAPIHadoopFile(xxx).repartition(2).map(xxxx)val df = spark.read.json("/user/iteblog/json").repartition(4).map(xxxx)val df = spark.read.json("/user/iteblog/json").coalesce(4).map(x w397090770 6年前 (2019-01-24) 8154℃ 0评论12喜欢
Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过下面的命令来启动Hadoop历史服务器[code lang="JAVA"]$ sbin/mr-jobhistory-daemon.sh start historyserver w397090770 11年前 (2014-02-17) 29784℃ 8评论30喜欢
摘要:本文是来自米哈游大数据部对于Flink在米哈游应用及实践的分享。 本篇内容主要分为四个部分: 1.背景介绍 2.实时平台建设 3.实时数仓和数据湖探索 4.未来发展与展望 作者:实时计算负责人 张剑 背景介绍 米哈游成立于2011年,致力于为用户提供美好的、超出预期的产品与内容。公司陆续推出了 w397090770 3年前 (2022-03-21) 1627℃ 1评论6喜欢
以较低的硬件成本扩展我们的数据基础设施,同时保持高性能和服务可靠性并非易事。 为了适应 Uber 数据存储和分析计算的指数级增长,数据基础设施团队通过结合硬件重新设计软件层,以扩展 Apache Hadoop® HDFS :HDFS Federation、Warm Storage、YARN 在 HDFS 数据节点上共存,以及 YARN 利用率的提高提高了系统的 CPU 和内存使用效率将多 w397090770 3年前 (2021-10-21) 430℃ 0评论3喜欢
# 总核数 = 物理CPU个数 X 每颗物理CPU的核数 # 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数# 查看物理CPU个数cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l# 查看每个物理CPU中core的个数(即核数)cat /proc/cpuinfo| grep "cpu cores"| uniq# 查看逻辑CPU的个数cat /proc/cpuinfo| grep "processor"| wc -l复制代码 查看CPU信息(型号)ca w397090770 3年前 (2021-11-01) 782℃ 0评论3喜欢
2021年2月4日,负责维护 Docker 引擎的 Justin Cormack 在 Docker 官方博客宣布把 Docker 发行版(Docker Distribution)捐献给了 CNCF,全文如下:我们很高兴地宣布,Docker 已经把 Docker 发行版(Docker Distribution)捐献给了 CNCF。Docker 致力于开源社区和我们许多项目的开放标准,这一举动将确保 Docker 发行版有一个广泛的团队来维护许多注册中心 w397090770 4年前 (2021-02-06) 288℃ 0评论2喜欢
最近在做给博客添加上传PDF的功能,但是在测试上传文件的过程中遇到了413 Request Entity Too Large错误。不过这个无错误是很好解决的,这个错误的出现是因为上传的文件大小超过了Nginx和PHP的配置,我们可以通过以下的方法来解决:一、设置PHP上传文件大小限制 PHP默认的文件上传大小是2M,我们可以通过修改php.ini里面的 w397090770 9年前 (2015-08-17) 20759℃ 0评论6喜欢
本系列文章翻译自:《scala data analysis cookbook》第二章:Getting Started with Apache Spark DataFrames。原书是基于Spark 1.4.1编写的,我这里使用的是Spark 1.6.0,丢弃了一些已经标记为遗弃的函数。并且修正了其中的错误。 一、从csv文件创建DataFrame 如何做? 如何工作的 附录 二、操作DataFrame w397090770 9年前 (2016-01-16) 6559℃ 0评论16喜欢
大年初二Apache CarbonData迎来了第四个稳定版本CarbonData 1.0.0。CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。CarbonData 1.0.0版本,一共带来了80+ 个新特性,并且有100+ 个bugfi w397090770 8年前 (2017-01-29) 2774℃ 0评论6喜欢
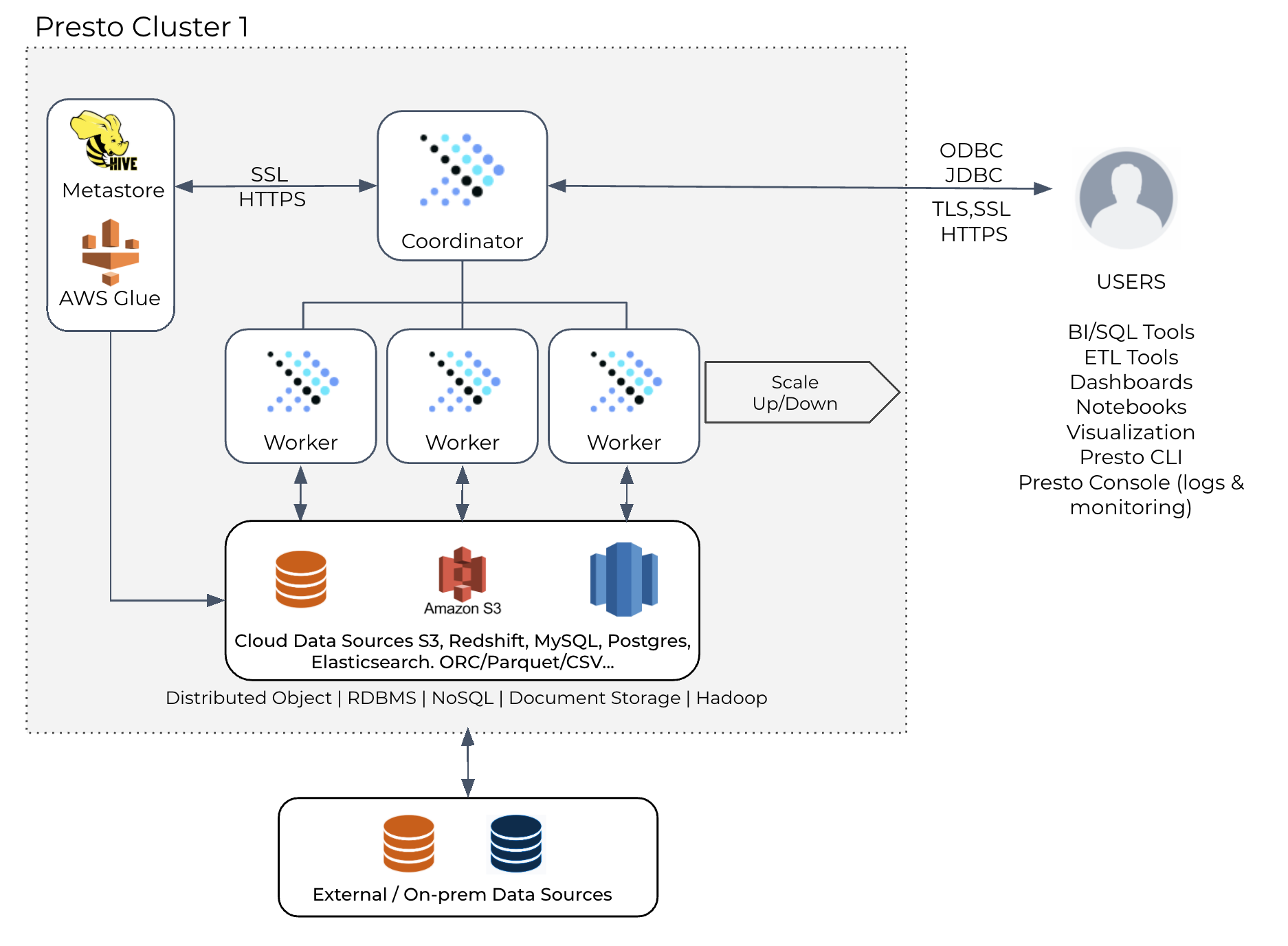
概述Presto 最初设计是对数据仓库中的数据运行交互式查询,但现在它已经发展成为一个位于开放数据湖分析之上的统一 SQL 引擎,用于交互式和批处理工作负载,数据湖上的流行工作负载包括:报告和仪表盘:这包括为内部和外部开发人员提供自定义报告以获取业务洞察力,以及许多使用 Presto 进行交互式 A/B 测试分析的组织 w397090770 3年前 (2021-11-14) 1384℃ 0评论1喜欢
在今年的5月22号,Flume-ng 1.5.0版本正式发布,关于Flume-ng 1.5.0版本的新特性可以参见本博客的《Apache Flume-ng 1.5.0正式发布》进行了解。关于Apache flume-ng 1.4.0版本的编译可以参见本博客《基于Hadoop-2.2.0编译flume-ng 1.4.0及错误解决》。本文将讲述如何用Maven编译Apache flume-ng 1.5.0源码。一、到官方网站下载相应版本的flume-ng源码[code lan w397090770 10年前 (2014-06-16) 20781℃ 23评论14喜欢
在Scala中存在case class,它其实就是一个普通的class。但是它又和普通的class略有区别,如下:1、初始化的时候可以不用new,当然你也可以加上,普通类一定需要加new;[code lang="scala"]scala> case class Iteblog(name:String)defined class Iteblogscala> val iteblog = Iteblog("iteblog_hadoop")iteblog: Iteblog = Iteblog(iteblog_hadoop)scala> val iteblog w397090770 9年前 (2015-09-18) 38514℃ 1评论71喜欢
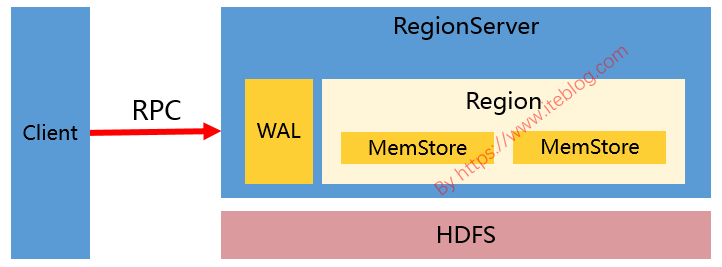
我们知道,一张 HBase 表包含一个或多个列族。HBase 的官方文档中关于 HBase 表的列族的个数有两处描述:A typical schema has between 1 and 3 column families per table. HBase tables should not be designed to mimic RDBMS tables. 以及 HBase currently does not do well with anything above two or three column families so keep the number of column families in your schema low. 上面两句话其实都是 w397090770 6年前 (2019-01-01) 4426℃ 1评论13喜欢
一、介绍 FairScheduler是一个资源分配方式,在整个时间线上,所有的applications平均的获取资源。Hadoop NextGen能够调度多种类型的资源。默认情况下,FairScheduler只是对内存资源做公平的调度(分配)。当集群中只有一个application运行时,那么此application占用这个集群资源。当其他的applications提交后,那些释放的资源将会被分配给新的 w397090770 9年前 (2015-12-03) 12057℃ 12评论15喜欢
本文主要盘点了 2017 年晋升为 Apache Top-Level Project (TLP) 的大数据相关项目,项目的介绍从孵化器毕业的时间开始排的,一共十二个。Apache Beam: 下一代的大数据处理标准Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的Apache孵化项目,被认为是继MapReduce,GFS和BigQuery等之后,Google在大数据处理领域对开源社区的 w397090770 7年前 (2018-01-01) 3480℃ 0评论10喜欢
Hadoop Streaming 是 Hadoop 提供的一个 MapReduce 编程工具,它允许用户使用任何可执行文件、脚本语言或其他编程语言来实现 Mapper 和 Reducer 作业。比如下面的例子[code lang="bash"]mapred streaming \ -input myInputDirs \ -output myOutputDir \ -mapper /bin/cat \ -reducer /usr/bin/wc[/code]Hadoop Streaming程序是如何工作的Hadoop Streaming 使用了 Unix 的标准 w397090770 8年前 (2017-03-21) 9994℃ 0评论15喜欢
Short URL or tiny URL is an URL used to represent a long URL. For example, http://tinyurl.com/45lk7x will be redirect to http://www.snippetit.com/2008/10/implement-your-own-short-url.There are 2 main advantages of using short URL: Easy to remember - Instead of remember an URL with 50 or more characters, you only need to remember a few (5 or more depending on application's implementation). More portable - Some systems have limi w397090770 12年前 (2013-04-15) 20484℃ 0喜欢
我们都知道,目前 Apache Beam 仅仅提供了 Java 和 Python 两种语言的 API,尚不支持 Scala 相关的 API。基于此全球最大的流音乐服务商 Spotify 开发了 Scio ,其为 Apache Beam 和 Google Cloud Dataflow 提供了Scala API,使得我们可以直接使用 Scala 来编写 Beam 应用程序。Scio 开发受 Apache Spark 和 Scalding 的启发,目前最新版本是 Scio 0.3.0,0.3.0版本之前依赖 w397090770 7年前 (2017-07-25) 1269℃ 0评论7喜欢
一、背景介绍1. 需要解决的业务痛点推荐系统对于推荐同学来说,想知道一个推荐策略在不同人群中的推荐效果是怎么样的。运营对于运营的同学来说,想知道在广东省的用户中,最火的广东地域内容是哪些?方便做地域 push。审核对于审核的同学,想知道过去 5 分钟游戏类被举报最多的内容和账号是哪些, zz~~ 3年前 (2021-10-08) 466℃ 0评论0喜欢
WordPress 的自定义字段就是文章的meta 信息(元信息),利用这个功能,可以扩展文章的功能,是学习WordPress 插件开发和主题深度开发的必备。对自定义字段的操作主要有四种:添加、更新(修改)、删除、获取(值)。 1、首先自定义字段的添加函数,改函数可以为文章往数据库中添加一个字段:[code lang="php"]<?php add_ w397090770 10年前 (2015-04-30) 3527℃ 0评论8喜欢
Apache Flume: Distributed Log Collection for Hadoop于2013年07月出版,全书共108页。 w397090770 9年前 (2015-08-25) 2851℃ 1评论4喜欢
Docker 为我们提供了大量的命令,直接在终端运行 docker --help 即可查看 Docker 支持的命令。如果需要查看具体命令的使用方式,可以使用 docker COMMAND --help。Docker 提供了 55 条命令,由于篇幅的原因,这里将介绍 Docker 常用的命令,其他的可以参见 Docker 官方文档。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号 w397090770 5年前 (2020-02-04) 331℃ 0评论3喜欢
Apache Spark于北京时间2015年07月16日05点正式发布。Spark 1.4.1主要是维护版本,包含了大量的稳定性修复。该版本是基于branch-1.4分支。社区推荐所有1.4.0使用升级到这个稳定版本。此版本有85位开发者参与。 Spark 1.4.1包含了大量的Bug修复,这些Bug出现在Spark的DataFrame、外部数据源支持以及其他组建的一些bug修复。一些比较重要 w397090770 9年前 (2015-07-16) 4361℃ 0评论10喜欢
下面论文均为大数据和分布式比较经典的论文,包括:CAP、BASE、2PC、一致性协议、一致性哈希、逻辑时钟、Leases 等。如果大家还有比较好的论文,欢迎在下面评论。分布式理论 Time, Clocks, and the Ordering of Events in a Distributed System Reaching Agreement in the Presence of Faults The Byzantine General Problem (CAP) Brewer's Conjecture and the Feasibility of w397090770 8年前 (2017-02-15) 3677℃ 0评论10喜欢